





A medida que evoluciona la ingeniería de datos moderna, DBT (Data Build Tool) ha surgido como un cambio de juego para los conductos ELT, simplificando las transformaciones, mejorando la eficiencia y garantizando la integridad de los datos. En nuestro proyecto, dbt desempeñó un papel crucial en la automatización de los flujos de trabajo, la reducción del código redundante y la racionalización de los procesos de datos. Este artículo proporciona una visión en profundidad de cómo dbt mejoró el rendimiento de nuestro proyecto y por qué es una herramienta esencial para cualquier equipo de datos.
Los ingenieros de datos a menudo se encuentran con varios retos a la hora de crear y mantener pipelines de datos:
- ETL complejas: Las herramientas ETL tradicionales requieren un gran esfuerzo de ingeniería para gestionar las dependencias y transformaciones.
- Desarrollo y despliegue lentos: escribir, probar y desplegar transformaciones puede llevar mucho tiempo.
- Problemas de calidad de los datos: Es difícil garantizar la coherencia de los datos, gestionar los duplicados y realizar comprobaciones de integridad.
- Almacenamiento y optimización del rendimiento: Gestionar grandes conjuntos de datos de forma eficiente sin cálculos innecesarios es todo un reto.
- Falta de control de versiones: los procesos ETL tradicionales carecen de control de versiones basado en Git, lo que dificulta la colaboración.
- Documentación manual y seguimiento del linaje: comprender las dependencias y transformaciones suele ser tedioso.
Para superar estos retos, utilizamos dbt en nuestros proyectos.
Comprensión de dbt y sus características clave
dbt (Data Build Tool) es una herramienta de ingeniería analítica de código abierto que permite a los equipos de datos transformar datos sin procesar dentro del almacén utilizando SQL. Garantiza que la lógica de transformación sea modular, reutilizable y fácil de mantener. dbt opera dentro del paradigma ELT (Extract, Load, Transform), centrándose en las transformaciones después de que los datos se hayan cargado en el almacén.
Características principales de dbt
- Transformaciones SQL: Permite transformaciones directamente en SQL, haciéndolo accesible a analistas e ingenieros.
- Modelos modulares y reutilizables: Utiliza macros Jinja y modelos reutilizables para garantizar un código limpio y DRY (Don’t Repeat Yourself).
- Pruebas y comprobaciones de calidad de datos integradas: proporciona validación de datos para garantizar la integridad y la fiabilidad.
- Control de versiones e integración CI/CD: admite versiones basadas en Git y despliegues automatizados.
- Documentación automatizada y linaje de datos: genera documentación y visualiza las dependencias, mejorando la transparencia.
- Gestión de dependencias: garantiza que los modelos se ejecuten en la secuencia correcta mediante la función ref().
- Procesamiento incremental de datos: Procesa sólo los datos nuevos o modificados, reduciendo los costes computacionales.
- Compatibilidad entre almacenes: funciona con Snowflake, Redshift, BigQuery y PostgreSQL, entre otros.
- Rendimiento ELT optimizado: Transforma los datos directamente en el almacén, aprovechando las modernas arquitecturas en la nube para obtener velocidad y escalabilidad.
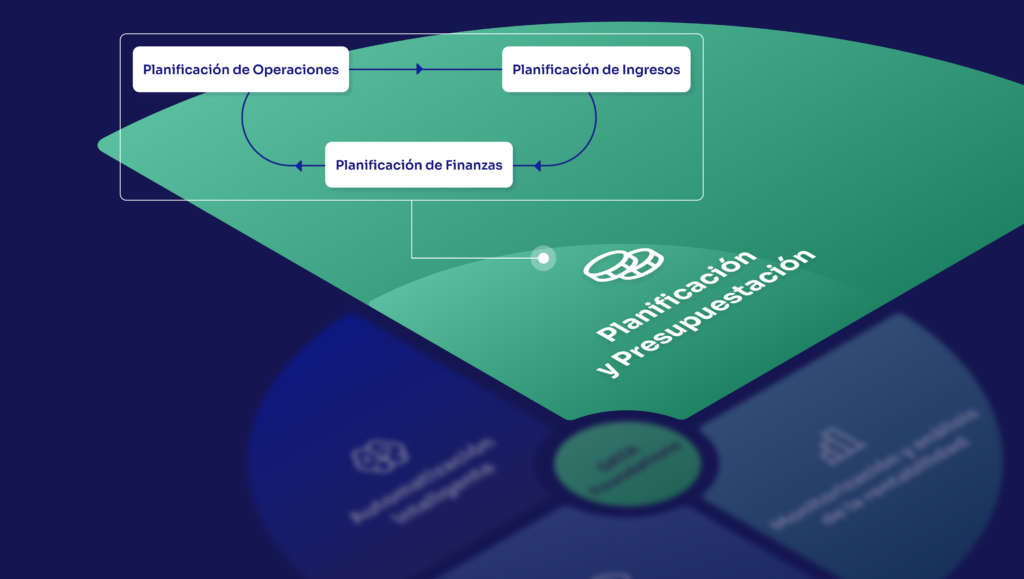
¿Cómo aplicamos dbt en nuestros proyectos?
Nuestros proyectos constan de tres capas de datos clave, en las que utilizamos estratégicamente las opciones de materialización de dbt:
Materializaciones optimizadas para un procesamiento de datos eficiente
Capa de almacenamiento (vistas): se utilizó la materialización de vistas para evitar la duplicación innecesaria de datos y mantener la dinámica de las transformaciones.
Capa intermedia (modelos efímeros): materialización efímera implementada para cálculos temporales, lo que reduce los costes de almacenamiento.
Capa de almacén (instantáneas): se utilizó la materialización de instantáneas para realizar un seguimiento de los cambios históricos de las dimensiones de cambio lento (SCD).
Beneficios:
- Reducción de los costes de almacenamiento al evitar la creación innecesaria de tablas.
- Mejora del rendimiento de las consultas mediante transformaciones eficientes en cada capa.
- Mejora de la modularidad y la capacidad de mantenimiento de las transformaciones.
Estandarización y reutilización de código con macros
Generación de claves sustitutas – Creación de macros para generar claves primarias únicas.
Automatización de las actualizaciones de las tablas de auditoría – Estandarización de las actualizaciones de las tablas de auditoría en diferentes modelos.
Carga de registros recientes – Implementación de una macro para recuperar sólo los registros más recientes para el procesamiento incremental.
Estandarización de los nombres de columna: se garantizó la coherencia de los nombres aplicando automáticamente prefijos y sufijos a los nombres de columna en la capa de preparación.
Beneficios:
- Reducción de la duplicación de código, lo que hace que las transformaciones sean más eficientes.
- Mejora de la gobernanza de los datos con convenciones de nomenclatura coherentes.
- Lógica de transformación centralizada, simplificando el mantenimiento.
Generación de SQL dinámico mediante plantillas Jinja
Consultas parametrizadas – En lugar de codificar valores en las consultas SQL, utilizamos variables Jinja para hacerlas dinámicas y reutilizables. Esto nos permitió generar consultas dinámicamente basadas en diferentes valores de entrada.
Selección dinámica del modelo – Aplicamos lógica condicional para determinar la ejecución del modelo en función de las dependencias.
Componentes SQL reutilizables: se crearon consultas basadas en plantillas para estandarizar las transformaciones en varios modelos.
Beneficios:
- Mejora de la flexibilidad ajustando dinámicamente la lógica SQL sin codificar valores.
- Reducción del esfuerzo manual para modificar las consultas SQL en todos los modelos.
- Permitió una rápida adaptación a los cambiantes requisitos empresariales.
Automatización de procesos con Post-Hooks
Comprobación de la calidad de los datos: ejecución de consultas posteriores al gancho para validar los datos después de la carga.
Registro y auditoría: actualización automática de los registros de auditoría tras las transformaciones.
Limpieza y mantenimiento de tablas: se aseguraba de que las tablas temporales se eliminaban o actualizaban después del procesamiento.
Beneficios:
- Reducción de la intervención manual, garantizando una ejecución sin problemas.
- Mejora de la calidad de los datos mediante la automatización de las comprobaciones de validación.
- Mantenimiento de un almacén de datos limpio y eficiente.
Mejorar la fiabilidad de los datos con pruebas y documentación
Aplicación de pruebas de dbt integradas (por ejemplo, valores únicos, no nulos, aceptados) para garantizar la integridad de los datos.
Desarrollo de pruebas personalizadas para validar la lógica empresarial y la precisión de la transformación.
Incorporación de descripciones de modelos y documentación a nivel de columna.
Aprovechamiento de la documentación dbt generada automáticamente para proporcionar visibilidad de las dependencias y transformaciones.
Beneficios:
- Aumento de la confianza y fiabilidad de los datos mediante la aplicación de comprobaciones de calidad.
- Mejora de la gobernanza de los datos gracias a una documentación clara.
- Permitió una colaboración fluida con una lógica de transformación transparente.
Como asegurar la calidad con Great Expectations
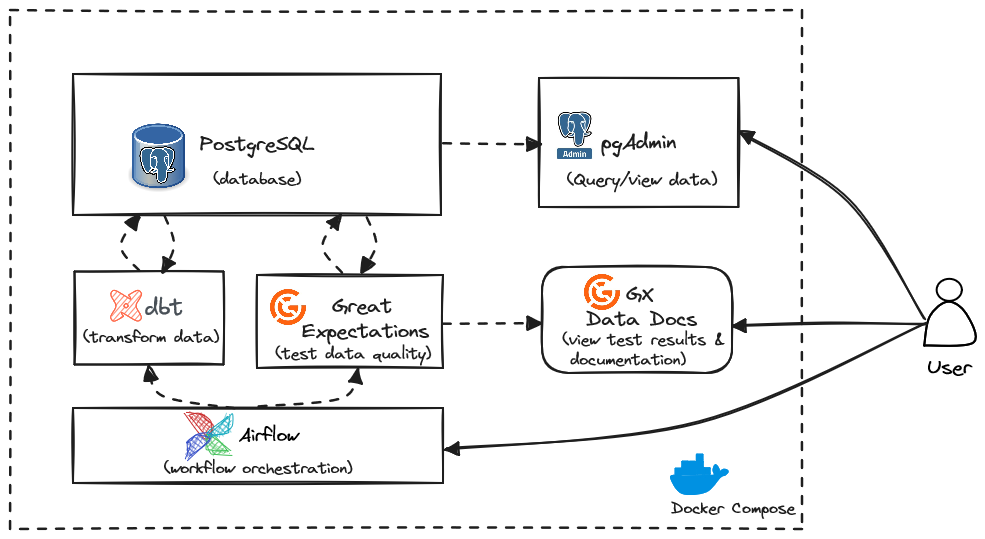
A modo de conclusión, nuestra experiencia con dbt demostró su inmenso valor en la ingeniería de datos moderna. Al aprovechar la arquitectura modular de dbt, las pruebas automatizadas y las estrategias de materialización, mejoramos significativamente la eficiencia, la capacidad de mantenimiento y la calidad de los datos de nuestro proyecto. Para cualquier equipo de datos que busque optimizar su canalización ELT, dbt proporciona una solución escalable, rentable y altamente adaptable.
Si tiene alguna pregunta o necesita ayuda con dbt, no dudes en contactarnos conmigo. Estaremos encantados de ayudarle y compartir conocimientos basados en nuestra experiencia.