












Hay una conversación que se repite en casi todos los equipos de datos que conocemos. Alguien del negocio pregunta por un dato. El equipo de datos lo busca en el warehouse, no encuentra el contexto que necesita para responder con seguridad, y acaba preguntando a la persona que lleva más tiempo en la empresa. Esa persona abre un Excel.
No es un fallo del equipo. Es el síntoma de un problema estructural que nadie ha resuelto todavía.
El equipo de datos no elige Excel
Cuando alguien de fuera del mundo de los datos imagina a un Data Engineer o un Data Manager, probablemente no los imagina trabajando en Excel. Los imagina con SQL, con Python, con dashboards en Looker o con pipelines en dbt. Y en su mayor parte, así es.
Pero hay una categoría de información que no cabe en ninguna de esas herramientas. Y esa información acaba, inevitablemente, en una hoja de cálculo.
No porque el equipo no sepa hacer las cosas de otra forma. Sino porque no existe otra herramienta específica para hacerlo.
Qué es lo que no cabe en el warehouse
El data warehouse es extraordinariamente bueno para almacenar y procesar datos transaccionales a escala. Millones de filas de ventas, clics, eventos, transacciones. Todo eso vive perfectamente en BigQuery o Snowflake.
Lo que no vive bien ahí es el contexto de esos datos.
¿Qué es un cliente activo según el criterio de negocio actual? ¿Qué valores son válidos para el campo tipo_canal? ¿Cuándo se decidió que los clientes con más de 180 días sin comprar pasaban a la categoría de inactivos, y quién lo decidió? ¿Qué excepción aplica a los clientes del segmento corporativo?
Esas preguntas tienen respuesta. Pero esa respuesta no está en una tabla de BigQuery. Está en la memoria de alguien, en un email de hace dos años, en una reunión cuyas notas nadie guardó bien, o — con suerte — en un Excel que alguien creó para intentar centralizar todo eso.
El Excel como solución de emergencia permanente
El problema con usar Excel para esto no es Excel en sí. Excel es una herramienta brillante para lo que fue diseñada.
El problema es que Excel no fue diseñado para gobernar datos maestros en equipo. Y cuando lo usas para eso, aparecen los síntomas conocidos:
Versiones múltiples. El Excel de clientes tiene cuatro versiones en cuatro carpetas distintas. Nadie sabe cuál es la definitiva. Cuando hay discrepancias en un informe, la primera pregunta es siempre “¿qué versión estabas usando?”.
Sin propietario claro. ¿Quién es responsable de mantener ese Excel actualizado? En teoría, todos. En la práctica, nadie. Hasta que hay un problema.
Sin validación. Cualquier persona con acceso puede escribir cualquier cosa en cualquier celda. No hay reglas. No hay alertas. No hay forma de saber si el dato que acaban de introducir es correcto.
Sin auditoría. ¿Quién cambió ese valor y cuándo? Excel no lo sabe. Si alguien modificó un criterio de clasificación el mes pasado, no hay registro de ello a menos que alguien lo haya documentado manualmente.
Sin sincronización. El Excel vive desconectado del warehouse. Cuando algo cambia en el Excel, alguien tiene que acordarse de actualizarlo también en el sistema. A veces lo hace. A veces no.
Por qué el equipo lo sigue usando
Con todo eso, ¿por qué el equipo de datos sigue usando Excel para gestionar el contexto?
La respuesta es simple: porque no tiene otra opción.
No hay una herramienta específica para gestionar datos contextuales de la forma en que se gestionan los datos transaccionales. Los catálogos de datos existen, pero tienen una implementación compleja y están pensados para el inventario, no para la gestión activa. Las wikis y documentos son estáticos. Los sistemas de MDM tradicionales son proyectos de consultoría de meses con costes que solo tienen sentido para organizaciones enterprise con equipos dedicados.
Para un equipo de datos de tamaño medio que necesita gobernar sus datos maestros hoy, Excel es literalmente la única opción accesible.
El coste que nadie calcula
El coste de este problema raramente aparece en un informe de gestión. No tiene una línea en el presupuesto. Pero existe.
Cada vez que un analista dedica dos horas a reconciliar versiones distintas de los mismos datos, ese tiempo tiene un coste. Cada vez que un cierre de mes se alarga porque los datos no cuadran y nadie sabe cuál es la fuente correcta, ese retraso tiene un coste. Cada vez que un proyecto de IA se para porque los datos de entrenamiento no están bien definidos y validados, esa paralización tiene un coste.
Y más allá del tiempo, hay un coste de confianza. Cuando el negocio no puede confiar en los datos que le da el equipo de datos — no porque el equipo haga mal su trabajo, sino porque el contexto de esos datos vive en sistemas informales y no gobernados — la relación entre datos y decisión se deteriora.
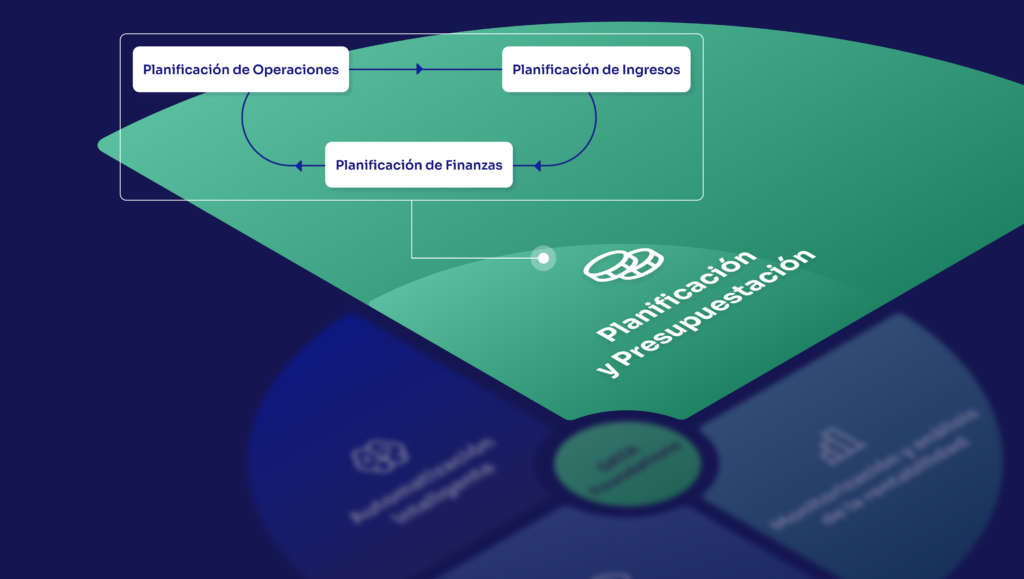
Qué cambiaría si existiera la herramienta correcta
Imagina que el catálogo de clientes no vive en un Excel compartido en Teams sino en un sistema con las siguientes características:
Cada campo tiene un tipo, una validación y un propietario asignado. Si alguien introduce un valor que no cumple las reglas, el sistema lo rechaza antes de guardar. Cuando alguien propone un cambio en los criterios de clasificación, hay un flujo de revisión — el cambio queda en borrador hasta que el responsable lo aprueba. Cada aprobación queda registrada con fecha, usuario y versión. Y cuando los datos se aprueban, se sincronizan automáticamente con BigQuery o Snowflake.
El cierre de mes ya no empieza con “¿qué versión del Excel estábamos usando?” porque hay una sola versión, aprobada, con historial completo.
Eso no es ciencia ficción. Es lo que debería haber existido hace tiempo.
El equipo de datos merece mejores herramientas
El equipo de datos no usa Excel porque quiere. Lo usa porque no tiene otra cosa.
Durante años, la industria ha invertido masivamente en hacer más potente la capa analítica — warehouses más rápidos, pipelines más robustos, visualizaciones más sofisticadas. Y todo eso es valioso.
Pero la capa de gobierno — el contexto que hace que la analítica tenga sentido — ha quedado relegada a hojas de cálculo y documentos informales. Y esa capa es la base de todo. Sin datos bien gobernados, la analítica miente. Sin datos bien contextualizados, la IA alucina.
Es hora de que el equipo de datos tenga una herramienta específica para gobernar lo que más importa: el conocimiento que rodea a los datos.